

در حالی که هوش مصنوعی ، یادگیری ماشینی و یادگیری عمیق اصطلاحات رایجی هستند که این روزها در همه جا می شنویم، تصورات غلط زیادی در مورد معنای واقعی این عبارات وجود دارد. بسیاری از شرکت ها ادعا می کنند که نوعی از هوش مصنوعی (AI) را در برنامه ها یا خدمات خود گنجانده اند، اما این در عمل به چه معناست؟
هوش مصنوعی
به طور کلی، زمانی که یک دستگاه، عملکردهای شناختی را طبق ذهن انسان ها تقلید می کند (مانند یادگیری و حل مسئله) نمایانگر مفهوم “هوش مصنوعی” است. در سطح ابتدایی تر، هوش مصنوعی فقط می تواند یک قانون برنامه ریزی شده باشد که به دستگاه می گوید و در شرایط خاص به شیوه خاصی رفتار کند. به عبارت دیگر ، هوش مصنوعی نمی تواند بیش از چندین عبارت if-else باشد. عبارت if-else یک قاعده ساده است که توسط یک انسان برنامه ریزی شده است. رباتی را در حال حرکت در جاده در نظر بگیرید. یک قانون برنامه ریزی شده برای آن ربات می تواند این باشد:

بنابراین، هنگامی که ما در مورد هوش مصنوعی صحبت می کنیم، ارزش آن را دارد که دو زیر شاخه خاص AI را در نظر بگیریم: یادگیری ماشین و یادگیری عمیق.
تفاوت یادگیری ماشین با یادگیری عمیق
اکنون که معنای هوش مصنوعی را بهتر درک کرده ایم، می توانیم نگاهی دقیق تر به یادگیری ماشین و یادگیری عمیق بیاندازیم تا تمایز روشنی بین این دو ایجاد شود.
تفاوت هوش مصنوعی و یادگیری ماشین و یادگیری عمیق
- هوش مصنوعی: برنامه ای است که می تواند از حس، استدلال، عمل و سازگاری برخوردار باشد.
- یادگیری ماشین: الگوریتم هایی که عملکرد آنها با قرار گرفتن در معرض داده های بیشتر در طول زمان بهبود می یابد.
- یادگیری عمیق: زیر مجموعه ای از یادگیری ماشین که در آن شبکه های عصبی چند لایه از حجم وسیعی از داده ها آموزش می گیرند.
یادگیری ماشین تکنولوژی جدیدی نیست
یادگیری ماشین چیست؟ ما می توانیم یادگیری ماشین را مجموعه ای از الگوریتم ها بدانیم که داده ها را تجزیه و تحلیل می کنند، از آن درس می گیرند و بر اساس آن بینش های آموخته، تصمیم گیری آگاهانه انجام می دهد.
یادگیری ماشین می تواند منجر به انواع کارهای خودکار شود و تقریباً بر همه صنایع تأثیر می گذارد، از جستجوی بدافزارهای امنیتی فناوری اطلاعات گرفته تا پیش بینی آب و هوا و دلالان سهام که به دنبال معاملات مطلوب هستند. برای دستیابی به توابع و نتایج مورد نیاز، یادگیری ماشین نیاز به ریاضیات پیچیده و کدنویسی زیادی دارد. علاوه بر این، یادگیری ماشین از الگوریتم های کلاسیک برای انواع مختلف امور مانند خوشه بندی، رگرسیون یا طبقه بندی استفاده می کند. ما باید این الگوریتم ها را بر روی حجم زیادی از داده ها آموزش دهیم. هرچه داده های بیشتری برای الگوریتم خود ارائه دهید، مدل شما بهتر می شود.
وقتی شخصی می گوید که با الگوریتم یادگیری ماشینی کار می کند، می توانید با پرسیدن اینکه “تابع هدف چیست؟” متوجه ارزش کلی آن شوید.
یادگیری ماشین یک زمینه نسبتا قدیمی است و شامل روش ها و الگوریتم هایی است که ده ها سال از عمر آنها می گذرد، برخی از آنها از دهه ۱۹۶۰ تاکنون وجود دارند. این الگوریتم های کلاسیک شامل طبقه بندی کننده Naïve Bayes و ماشینهای بردار پشتیبان (Support Vector Machine) هستند که هر دو اغلب در طبقه بندی داده ها استفاده می شوند. علاوه بر طبقه بندی، الگوریتم های تجزیه خوشه ای مانند K-Means و خوشه بندی مبتنی بر درخت نیز وجود دارد. برای کاهش ابعاد داده ها و درک بیشتر ماهیت آن، یادگیری ماشین از روش هایی مانند تجزیه و تحلیل مولفه های اصلی و tSNE استفاده می کند.
مولفه آموزشی مدل یادگیری ماشین به این معنی است که مدل سعی می کند تا در بعد خاصی بهینه سازی شود. به عبارت دیگر، مدلهای یادگیری ماشینی سعی می کنند خطای بین پیش بینی های خود و مقادیر اصلی و واقعی را به حداقل برسانند.
بدین منظور ما باید یک تابع خطا تعریف کنیم که به آن “تابع اتلاف” یا “تابع هدف” نیز می گویند، زیرا مدل دارای هدف است. این هدف می تواند طبقه بندی داده ها در دسته های مختلف، به عنوان مثال تصاویر گربه و سگ یا پیش بینی قیمت مورد انتظار سهام در آینده نزدیک باشد. وقتی شخصی می گوید که با الگوریتم یادگیری ماشینی کار می کند، می توانید با پرسیدن اینکه “تابع هدف چیست” متوجه ارزش کلی آن شوید.
چگونه خطا را به حداقل برسانیم؟
ما می توانیم پیش بینی مدل را با مقدار اصلی و حقیقی مقایسه کنیم و پارامترهای مدل را طوری تنظیم کنیم که دفعه بعد خطا بین این دو مقدار کوچکتر شود. این فرایند میلیون ها بار تکرار می شود تا زمانی که پارامترهای مدل تعیین کننده پیش بینی ها آنقدر خوب باشند که تفاوت بین پیش بینی های مدل و برچسب های اصلی و حقیقی تا حد ممکن کوچک شده باشد.
به طور خلاصه، مدل های یادگیری ماشین الگوریتم های بهینه سازی هستند. اگر آنها را درست تنظیم کنید، با حدس زدن و حدس زدن و حدس مجدد خطا را به حداقل می رسانند.
یادگیری عمیق
برخلاف “یادگیری ماشینی”، “یادگیری عمیق” زیر شاخه ای تازه از هوش مصنوعی است که بر اساس شبکه های عصبی مصنوعی ساخته شده است. از آنجا که الگوریتم های یادگیری عمیق نیز برای یادگیری و حل مشکلات به داده نیاز دارند، می توانیم آن را زیرمجموعه یادگیری ماشین نیز بنامیم. اصطلاحات یادگیری ماشین و یادگیری عمیق اغلب مترادف تلقی می شوند، اما این سیستم ها قابلیت های متفاوتی دارند. یادگیری عمیق از ساختار چند لایه ای از الگوریتم ها به نام شبکه عصبی استفاده می کند.
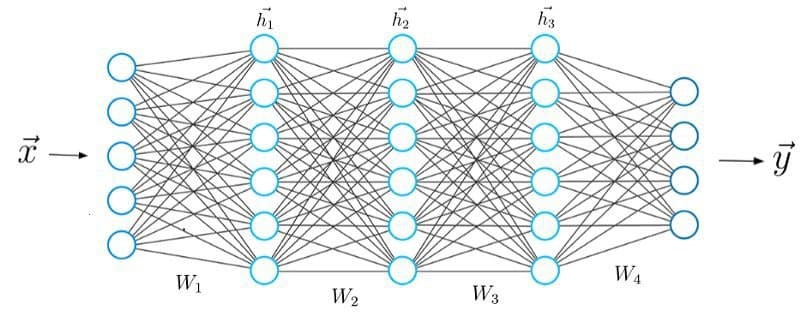
شبکه های عصبی مصنوعی دارای قابلیت های منحصر به فردی هستند که مدل های یادگیری عمیق را قادر می سازد تا کارهایی را به انجام برسانند که مدل های یادگیری ماشین هرگز قادر به انجام آنها نیستند.
همه پیشرفت های اخیر در زمینه هوش به سبب بهره وری از یادگیری عمیق است. بدون یادگیری عمیق، ما اتومبیل های خودران، چت بات یا دستیاران شخصی مانند الکسا و سیری نخواهیم داشت. گوگل ترجمه در سطح ابتدایی باقی می ماند و Netflix قادر نبود تشخیص دهد کدام فیلم یا سریال تلویزیونی را پیشنهاد کند.
ما حتی می توانیم تا جایی پیش برویم که بگوییم انقلاب صنعتی جدید توسط شبکه های عصبی مصنوعی و یادگیری عمیق هدایت می شود. این بهترین و نزدیک ترین رویکرد به هوش ماشینی واقعی است که ما تا کنون داشته ایم زیرا یادگیری عمیق دو مزیت عمده نسبت به یادگیری ماشینی دارد.
چرا یادگیری عمیق بهتر از یادگیری ماشین است؟
اولین مزیت یادگیری عمیق نسبت به یادگیری ماشین، افزونگی استخراج خصیصه است. مدتها قبل از استفاده از یادگیری عمیق، روش های سنتی یادگیری ماشین (تصمیم گیری درختی، SVM ، طبقه بندی Naive Bayes و رگرسیون استدلالی) محبوب ترین بودند. اینها در غیر این صورت به عنوان الگوریتم های مسطح شناخته می شوند. در این زمینه “مسطح” به این معنی است که این الگوریتم ها معمولا نمی توانند مستقیماً روی داده های خام (مانند .csv، تصاویر، متن و غیره) اعمال شوند؛ در عوض ما به یک مرحله پیش پردازش به نام استخراج خصیصه نیاز داریم.
عدم استخراج خصیصه
در استخراج خصیصه، ما یک نمایش انتزاعی از داده های خام ارائه می دهیم که الگوریتم های کلاسیک یادگیری ماشین می توانند برای انجام یک کار (به عنوان مثال طبقه بندی داده ها به چند دسته یا کلاس) استفاده کنند. استخراج خصیصه ها معمولا بسیار پیچیده است و نیاز به آگاهی دقیق از حوزه مشکل دارد. برای دستیابی به نتایج مطلوب، این مرحله باید چندین بار تطبیق داده، آزمایش و تصحیح شود. مدل های یادگیری عمیق نیازی به استخراج خصیصه ندارند.
وقتی صحبت از مدل های یادگیری عمیق می شود، ما شبکه های عصبی مصنوعی داریم که نیازمند استخراج خصیصه نیستند. لایه ها به تنهایی قادر به یادگیری ضمنی داده های خام هستند.
یک مدل یادگیری عمیق یک نمایش انتزاعی و فشرده از داده های خام را در چندین لایه از شبکه عصبی مصنوعی تولید می کند. سپس ما از یک نمایش فشرده از داده های ورودی برای تولید نتیجه استفاده می کنیم. نتیجه می تواند برای مثال، طبقه بندی داده های ورودی به کلاس های مختلف باشد.
در طول فرآیند آموزش، شبکه عصبی این مرحله را برای به دست آوردن بهترین نمایش انتزاعی ممکن از داده های ورودی بهینه می کند. مدل های یادگیری عمیق برای انجام و بهینه سازی فرآیند استخراج خصیصه به هیچ مقدار تلاش دستی یا تلاش بسیار کمی نیاز دارند. به عبارت دیگر، استخراج ویژگی در فرآیندی که در یک شبکه عصبی مصنوعی و بدون ورود انسان انجام می شود، ساخته شده است.
اگر می خواهید از یک مدل یادگیری ماشین برای تعیین اینکه آیا یک تصویر خاص، ماشینی را نشان می دهد یا خیر استفاده کنید، ما انسان ها ابتدا باید خصیصه های منحصر به فرد خودرو (شکل، اندازه، پنجره ها، چرخ ها و غیره) را شناسایی کرده، این خصیصه ها را استخراج کرده و آنها را به عنوان داده ورودی به الگوریتم بدهیم و آنگاه الگوریتم یادگیری ماشین طبقه بندی تصویر را انجام می دهد؛ یعنی در یادگیری ماشین، یک برنامه نویس باید مستقیما در فرایند طبقه بندی مداخله کند.
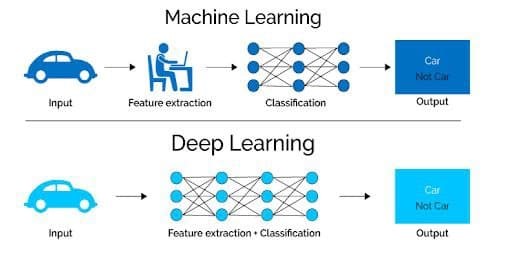
این امر در مورد هر کار دیگری که با شبکه های عصبی انجام دهید صدق می کند. داده های خام را به شبکه عصبی بدهید و بگذارید مدل بقیه کارها را انجام دهد.
عصر کلان داده ها
یکی دیگر از مزایای یادگیری عمیق و علت محبوبیت آن این است که از حجم عظیمی از داده ها استفاده می کند. عصر فناوری کلان داده ها، فرصت های عظیمی را برای نوآوری های جدید در یادگیری عمیق فراهم می کند.
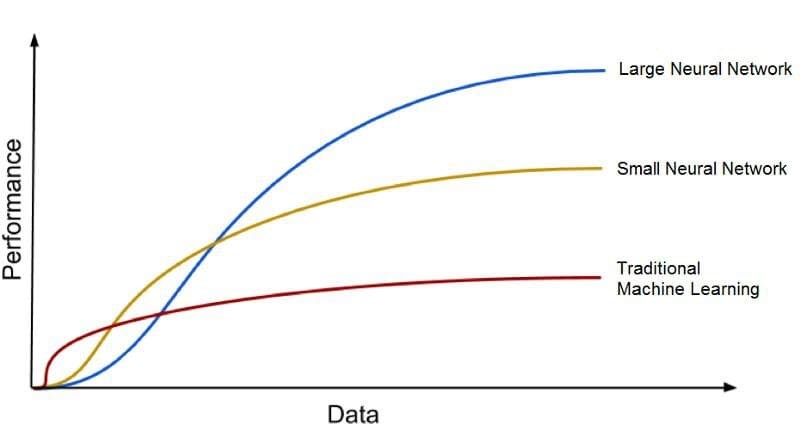
“مدلهای یادگیری عمیق” تمایل دارند دقت خود را با افزایش داده های آموزشی افزایش دهند، در حالی که “مدلهای یادگیری ماشینی سنتی” مانند SVM و طبقه بندی کننده Naïve Bayes پس از نقطه اشباع متوقف می شوند.
مدل های یادگیری عمیق با حجم بیشتری از داده ها، مقیاس بندی بهتری دارند. با نقل قول از اندرو Ng، دانشمند ارشد موتور جستجوی اصلی Baidu چین، بنیانگذار Coursera و یکی از رهبران پروژه مغز گوگل، میتوان گفت “اگر یک الگوریتم یادگیری عمیق یک موتور موشک باشد، داده ها سوخت هستند.”



