

بهتر است قبل از هر چیز، به تولید فکر کنید و برای آن برنامهریزی قابل اجرا داشته باشید؛ اینگونه اجازهی شکست و سقوط قبل از شروع را به پروژههای ماشین لرنینگ نخواهید داد.
به عنوان دانشمندان داده، یکی از وظایف ما، ایجاد طرح کلی برای هر پروژهی ماشین لرنیگ است. پروژه ممکن است یک پروژهی طبقهبندی، رگرسیون یا یادگیری عمیق کار باشد یا حتی تصمیمگیری در مورد مراحل پیشپردازش داده، مهندسی خصیصه، انتخاب خصیصه، متریک ارزیابی و الگوریتم. همچنین تنظیم فراپارامتر برای الگوریتمهای مذکور نیز به عهده ماست. ما زمان زیادی را صرف پرداختن به این مسائل میکنیم.
تمامی این موارد خوب و مطلوب هستند. اما موارد مهم دیگری نیز وجود دارند که باید هنگام ساخت یک سیستم عالی ماشین لرنینگ در نظر بگیرید. برای مثال، آیا تا به حال به این فکر کردهاید که وقتی مدلهای خود را در اختیار داشته باشیم، چگونه آنها را به کار خواهیم برد؟
من پروژههای ماشین لرنینگ زیادی دیدهام و بسیاری از آنها حتی قبل از شروع، شکست خوردند؛ زیرا از همان ابتدا برنامهای برای تولید نداشتند. به نظر من، الزامات فرآیند برای یک پروژهی موفق ماشین لرنینگ، با تفکر در مورد چگونگی و زمان تولید مدل آغاز میشود.
۱.در ابتدا یک خط مبنا ایجاد کنید.
من از شروع پروژههای ماشین لرنینگ در بیشتر شرکتها متنفرم!!! به من بگویید که آیا تا به حال چیزی شبیه به این شنیدهاید: «ما یک مدل پیشرفته ایجاد میکنیم که با دقت بیش از ۹۵٪ کار خواهد کرد.»
یا در مورد این چطور: «بیایید یک مدل سری زمانی بسازیم که خطای محاسبه ریشه دوم میانگین در آن، نزدیک به صفر باشد.»
چنین انتظاری از یک مدل، واقعا پوچ است؛ زیرا جهانی که ما در آن زندگی میکنیم کاملا غیر قطعی است. به عنوان مثال، در مورد تلاش برای پیشبینی مدلی که آیا فردا باران خواهد بارید یا خیر، یا اینکه آیا مشتری محصولی را دوست دارد یا نه، فکر کنید.
پاسخ به این سوالات ممکن است به بسیاری از ویژگیهایی بستگی داشته باشد که ما به آنها دسترسی نداریم. این نوع استراتژی به کسبوکار لطمه میزند؛ زیرا مدلی که قادر به برآورده کردن چنین انتظارات بالایی نباشد، شکست میخورد و از بین میرود.
برای جلوگیری از این نوع شکست، باید در شروع پروژه یک خط مبنا ایجاد کنید.
ولی خط مبنا چیست؟ خط مبنا یک معیار ساده است که به ما کمک میکند عملکرد فعلی یک کسبوکار را در انجام یک کار خاص، درک کنیم. اگر مدلها با این معیار مطابقت کامل یا حداقل شباهتی داشته باشند، ما در حوزه سود هستیم.
اگر کار در حال حاضر به صورت دستی انجام میشود، مطابقت کامل با معیار، به این معنی است که میتوانیم انجام آن را خودکار کنیم. حتی قبل از اینکه شروع به ایجاد مدل کنید، می توانید نتایج پایه را دریافت کنید.
برای مثال، بیایید تصور کنیم که از خطای ریشه دوم میانگین (RMSE) بهعنوان معیار ارزیابی برای مدل سریهای زمانی استفاده میکنیم و نتیجه به صورت X است. آیا X یک RMSE خوب است؟ در حال حاضر، این فقط یک عدد است. برای پی بردن به پاسخ سوالمان، ما به یک RMSE پایه نیاز داریم تا ببینیم آیا X یک مقدار بهتر یا بدتر از مدل قبلی یا یک مدل ذهنی است.
خط مبنا میتواند بسته به مدلی به وجود بیاید که در حال حاضر، برای همان کار استفاده میشود. همچنین میتوانید از یک مدل ذهنی ساده به عنوان خط مبنا استفاده کنید.
به عنوان مثال، در یک مدل سری زمانی، یک مبنای خوب برای هدف قرار دادن، پیشبینی روز آخر است، یعنی فقط پیشبینی عدد در روز قبل و محاسبه یک RMSE مبنا. اگر مدل شما نمیتواند حتی به این معیار ساده برسد، مطمئنا میدانیم که مدل توانایی مفید واقع شدن را نخواهد داشت.
برای طبقهبندی تصاویر چطور باید عمل کرد؟ شما میتوانید ۱۰۰۰ نمونه برچسبگذاری شده را بردارید و از افراد مختلف بخواهید آنها را طبقهبندی کنند. سپس، دقت انسانی میتواند مبنای شما باشد. اگر فردی نتواند دقت پیشبینی ۷۰ درصدی را به دست آورد، به دلایل مختلفی مانند پیچیده بودن کار یا ذهنی بودن آن (مانند پیشبینی احساسات بر اساس چهره یک فرد)، میتوانید زمانی که مدلهای شما به سطح عملکرد مشابهی رسیدند، فرآیند را خودکار کنید.
سعی کنید حتی قبل از ایجاد مدلهایتان، از عملکردی که قرار است به دست آورید آگاه باشید. داشتن برخی انتظارات غیرعادی، فقط شما و مشتریانتان را ناامید میکند و مانع از رسیدن پروژه به مرحله تولید میشود.
۲. یکپارچگی مداوم، راهی رو به جلو است.
فرض کنید اکنون مدل جدیدی را ایجاد کردهاید و این مدل، بهتر از مدل مبنا یا مدل فعلیتان عمل میکند. آیا باید به سمت تولید پیش رفت؟ در این مرحله شما دو انتخاب دارید:
- وارد یک حلقهی بیپایان برای بهبود بیشتر مدلتان شوید: من نمونههای بیشماری را دیدهام که در آن یک کسبوکار، تغییر سیستم فعلی را در نظر نمیگیرد و قبل از اینکه سیستم جدید را به سمت تولید سوق دهد، درخواست دریافت بهترین سیستم را دارد.
- مدل خود را در تنظیمات تولید آزمایش کنید. اطلاعات بیشتری در مورد آنچه ممکن است اشتباه پیش برود، دریافت کنید و سپس به بهبود مدل، با یکپارچگی مداوم ادامه دهید.
البته من طرفدار رویکرد دوم هستم. اندرو نگ در سومین دورهی عالی خود در تخصص یادگیری عمیق Coursera میگوید:
تلاش برای طراحی و ساختن سیستم عالی را شروع نکنید. در عوض، یک سیستم پایه را به سرعت بسازید و آموزش دهید؛ حتی اگر شده، در چند روز. حتی اگر سیستم اصلی از بهترین سیستمی که میتوانید بسازید، فاصلهی زیادی داشته باشد. بررسی نحوهی عملکرد سیستم اصلی بسیار ارزشمند است: شما به سرعت سرنخهایی را پیدا خواهید کرد که امیدوارکنندهترین مسیرها را برای سرمایهگذاری زمان، به شما نشان میدهند.
شعار ما باید این باشد که: انجام دادن، بهتر از تکامل یافتن است.
اگر مدل جدید شما بهتر از مدلی است که اکنون در حال تولید است یا بهتر از مدل مبناست، منطقی نیست که برای تولید منتظر بمانید.
۳. از تست A/B مطمئن شوید.
آیا واقعا مدل شما بهتر از خط مبنا است؟ شاید در تست بهتر عمل کند، اما آیا روی کل پروژه و در تنظیمات تولید به خوبی کار خواهد کرد؟ برای آزمایش اعتبار این فرض که آیا مدل جدید بهتر از مدل موجود است یا نه، میتوانید یک تست A/B انجام دهید. برخی از کاربران (گروه آزمایشی) پیشبینیهای مدل شما را میبینند و گروه دیگری از آنها (گروه کنترل) پیشبینیهای مدل قبلی را میبینند.
در واقع، این راه درستی برای استقرار مدل شماست. طی این پروسه ممکن است متوجه شوید که در واقع مدل شما آنقدرها که فکر میکردید، خوب نیست. به خاطر داشته باشید که نادرست بودن مدل، اتفاق بد و اشتباهی نیست. اشتباه آن است که پیشبینی نکنید شما هم ممکن است دچار اشتباه شوید. سریعترین راه برای از بین بردن کامل پروژه، پرهیز سرسختانه از مقابله با خطاپذیری خود است.
اشاره به دلیل عملکرد ضعیف مدل در تنظیمات تولید، ممکن است دشوار باشد، اما برخی از این دلایل ممکن یکی از موارد زیر باشند:
- ممکن است مشاهده کنید دادههایی که در زمان واقعی به دست میآیند به طور قابل توجهی، با دادههای آموزشی متفاوت هستند؛ به عنوان مثال توزیع دادههای آموزش و توزیع زمان واقعی داده متفاوت است. این مورد ممکن است در مدلهای طبقهبندی تبلیغاتی که اولویتهایشان در طول زمان تغییر میکند، اتفاق بیفتد.
- ممکن است خط پیشپردازش را به درستی انجام نداده باشید. به این معنی که برخی از ویژگیها را به اشتباه، در مجموعهی دادههای آموزشی خود قرار دادهاید که در زمان تولید در دسترس نخواهد بود. برای مثال، ممکن است متغیری به نام «COVID Lockdown(0/1)» را در مجموعه دادهها اضافه کنید. اگر چه ممکن است ندانید که در محیط تولید، قرنطینه تا چه مدت به قوت خود باقی خواهد ماند.
- شاید اشکالی در پیادهسازی وجود داشته باشد که حتی واحد بررسی کد، قادر به رفع آن نبوده است.
علت هرچه که باشد، چیزی که باید بیاموزیم این است که شما نباید با مقیاس کامل وارد تولید شوید. تست A/B همیشه یک راه عالی برای پیشرفت است. اگر متوجه شدید که مدل شما ناقص است، مدلی به عنوان جایگزین در نظر داشته باشید که به آن بازگردید؛ مانند یک مدل قدیمی. حتی اگر مدل شما خوب کار کند، ممکن است چیزهایی اشتباه پیش بروند که نمیتوانستید پیشبینی کنید و شما باید برای مواجهه با این موضوع آماده باشید.
۴. مدل شما ممکن است اصلا به مرحلهی تولید نرود.
بیایید تصور کنیم که یک مدل ماشین لرنینگ چشمگیر را ایجاد کردهاید که دقتی معادل ۹۰٪ ارائه میدهد، اما حدود ۱۰ ثانیه طول میکشد تا یک پیشبینی انجام شود یا برای پیشبینی نیاز به منابع زیادی باشد.
آیا این قابل قبول است؟ برای برخی موارد، شاید، اما به احتمال زیاد نه.
در گذشته، بسیاری از شرکتکنندگان مسابقات Kaggle، برای کسب رتبهی برتر در جدول امتیازات، گروههایی به نام گروه هیولا تشکیل میدادند. در ادامه یک مثال جالب برای برنده شدن در چالش طبقهبندی در Kaggle استفاده شده است.
مثال دیگر، چالش موتور میلیون دلاری نتفلیکس است. تیم نتفلیکس به دلیل هزینههای مهندسی، هرگز از راهحل برنده استفاده نکرد. این موارد همواره اتفاق میافتند: هزینه یا تلاشهای مهندسی برای تولید یک مدل پیچیده، به قدری زیاد است که پیشروی در آن، سودی نخواهد داشت.
بنابراین چگونه میتوانید مدلهای خود را دقیق و در عین حال به سادگی روی دستگاه بسازید؟
در اینجا، مفهوم مدل معلم و دانشآموز یا چکانش و دانش، مفید واقع میشود. در چکانش و دانش، ما یک مدل دانشآموز کوچکتر را بر یک مدل معلم بزرگتر آموزش دادهایم. هدف اصلی تقلید از مدل معلم است و این بهترین مدلی است که ما داریم. با مدل دانشآموزی که پارامترهای بسیار کمتری دارد، میتوانید برچسبها و احتمالات را از مدل معلم بگیرید و از آن به عنوان دادههای آموزشی برای مدل دانشآموز استفاده کنید. شهود پشت این موضوع این است که برچسبهای نرم، بسیار آموزندهتر از برچسبهای سخت هستند.
برای مثال، معلم برای طبقهبندی گربه و سگ ممکن است بگوید احتمال کلاسها برای گربه، ۸/۰ و برای سگ، ۲/۰ است.
چنین برچسبی آموزنده است؛ زیرا طبقهبندی دانشآموز میداند که تصویر نمایشگر یک گربه است، اما کمی شبیه به سگ است، یا اگر احتمالات هر دو مشابه باشد، طبقهبندی دانشآموز ممکن است از معلم تقلید کند و نسبت به آن مثال خاص اطمینان کمتری داشته باشد.
راه دیگر برای کاهش زمان اجرا و استفاده از منابع در زمان پیشبینی، این است که با استفاده از مدلهای سادهتر، کمی از دقت و عملکرد چشمپوشی کنید. در برخی موارد در زمان پیشبینی، قدرت محاسباتی زیادی در دسترس نخواهید داشت. گاهی اوقات حتی مجبور خواهید بود در منطقهای حاشیهای و غیرمتمرکز، پیشبینی کنید.
بنابراین لازم است مدل سبکتری داشته باشید. میتوانید مدلهای سادهتری بسازید یا از مدل چکانش و دانش برای چنین مواردی استفاده نمایید.
۵. حلقه نگهداری و بازخورد
دنیا ثابت نیست و وزن مدل شما هم ثابت نخواهد بود. دنیای اطراف ما به سرعت در حال تغییر است و آنچه دو ماه پیش قابل اجرا بود، ممکن است اکنون قابل اجرا نباشد. به نوعی، مدلهایی که میسازید بازتابی از جهان هستند و حال که دنیا در حال تغییر است، مدلهای شما باید بتوانند این تغییر را منعکس کنند.
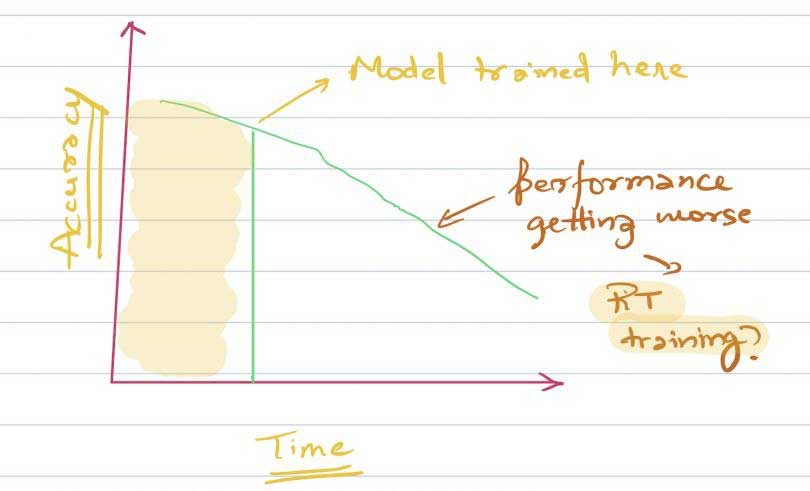
عملکرد مدل معمولا با گذشت زمان دچار نزول میشود. به همین دلیل در همان ابتدا باید به فکر راههایی برای ارتقای مدل خود به عنوان بخشی از چرخهی تعمیر و نگهداری باشید.
فرکانس چرخه، کاملا به مشکل تجاری که در تلاش برای حل آن هستید، بستگی دارد. به عنوان مثال در یک سیستم پیشبینی تبلیغات که در آن کاربران تمایل به بیثباتی دارند و الگوهای خرید به طور مداوم ظاهر میشوند، فرکانس باید بسیار بالا باشد. در مقابل، در یک سیستم تحلیل احساسات مروری، فرکانس نباید آنقدر زیاد باشد؛ زیرا زبان اغلب ساختار خود را تغییر نمیدهد.
من همچنین اهمیت حلقهی بازخورد در سیستم ماشین لرنینگ را تصدیق میکنم. فرض کنید که شما پیشبینی کردهاید که تصویر خاصی از یک سگ، با احتمال کم در طبقهبندی سگ قرار دارد. آیا میتوانیم از مثالهایی که احتمال درست بودن پیشبینیشان کم است، چیزی یاد بگیریم؟ میتوانید آن را به قسمت بررسی دستی بفرستید و تصمیم بگیرید که آیا میتوان از آن، برای آموزش مجدد مدل استفاده کرد یا خیر. به این ترتیب، طبقهبندی خود را در رویارویی با مواردی که از آنها مطمئن نیستید، آموزش میدهید.
زمانی که به تولید فکر میکنید، برنامهای برای آموزش، حفظ و بهبود مدل با استفاده از بازخورد نیز ارائه دهید.
نتیجهگیری و جمعبندی
این نکتهها برخی از مواردی است که من قبل از فکر کردن به تولید یک مدل، مهم تلقی میکنم.
اگرچه این فهرست جامعی از چیزهایی که باید دربارهی آنها فکر کنید و مشکلاتی که ممکن است پیش بیایند نیست، اما دفعهی بعد که یک سیستم ماشین لرنینگ ایجاد میکنید، میتوانید از این نکات به منظور شروع و تغذیهی افکارتان استفاده کنید.



